Bitcoin Cash Node Technical Bulletin
BCHN Network Architecture
Summary
- Introduction and rationale
- The general architecture
CConnman's threads- Benefits and impact
- Appendix: Description of relevant classes and files
Introduction and rationale
The aim of this technical bulletin is to describe the current inner workings of the network management of the Bitcoin Cash Node software. The targeted audience are developers related to the Bitcoin Cash Node software project.
Bitcoin Cash is a peer to peer network, so the network code is very important both from a functional and security viewpoint.
The current incarnation of the network code (as of v24.0.0) is based on the general architecture set by the original Satoshi code in Bitcoin v0.1.0/v0.1.3 (Reference).
The rationale for this documentation is the assessment of the benefits and impact of changing the general architecture with one that is more parallel (wrt peer communication). In the current implementation, the receiving network thread "commands" the rest of the application; moreover, only one incoming message at a time can be processed. Re-engineering this part of the application can have important performance improvements. No specific recommendations will be proposed in this report.
All of the following is based on BCHN v24.0.0 (at 1ef932b1b7).
The general architecture
The application has a globally scoped std::unique_ptr<CConnman> g_connman which, besides managing connections, as the name suggests, manages most of the aspects of networking. It is started
as the last step of initialization, after all other subsystems have are running. In doing so, the initialization thread essentially passes the control of the application to the network threads.
A CNode represents a node/peer, and it contains all of the information regarding the connection to that peer, including current network-level data buffers and application-level network CNetMessages.
g_connmanmaintains a vector of CNodes/connected peers.
Starting the CConnman will start the following threads:
netrunning theThreadSocketHandlerfunction, which is responsible for net sockets reading and writing of messages.msghandrunningThreadMessageHandlerwhich handles messages received from peers.addconrunningThreadOpenAddedConnectionsandopenconrunningThreadOpenConnectionswhich manage connections to manually-added and network-announced peers.
There is a level of decoupling here in that the net thread writes to the CNodes' vProcessMsg message list and reads
from the CNodes' vSendMsg message deque, while the msghand thread does the contrary, and they work in parallel.
One is a list and the other is a deque because of API requirements (specifically, deque lacks splice() used in the code).
CConnman's threads
The net thread is a straightforward read/write loop for network sockets and for each iteration it:
- Does some initializations
- Marks each node/peer as "selected for receiving", "selected for sending" or neither
- Accepts connections from new nodes/peers, if any
- Makes a copy of the
vNodesvector (to avoid concurrency issues and release locks quickly); for each node in the copied vector- if it was set for receiving, receive data and possibly transform it into
CNetMessages; add them tovProcessMsg(the node's list of messages to be processed). AlsoWakeMessageHandler. - otherwise, if it was set for sending,
SocketSendData - an
InactivityCheckis done for the node/peer
- if it was set for receiving, receive data and possibly transform it into
The msghand thread is a loop for application-level messages and it:
- Makes a copy of the
vNodesvector; for each node in the copied vector- processes a single message from the incoming
vProcessMsglist, if any (viaProcessMessages). Processing a message will often have the effect of sending some messages - for example when we recieve aGETDATA, we'll end up enqueing the requested data in thisCNode'svSendMsg(viaCConnman::PushMessage). If any of theCNodes has any more messages invProcessMsgthen thefMoreWorkflag will be set to true. - does a
SendMessages; this will maintain connection with the peer viaping/pong, exchange recent peers, manage IBD (?), sendinventories for recent blocks and transactions, sendgetdatafor transactions we're missing, and some other housekeeping regarding thisCNode
- processes a single message from the incoming
- If
fMoreWorkhas been set by any of theCNodes, the whole loop is repeated immediately; else it waits for the closest Poisson delay of theCNodes'nNextInvSendand repeats. Optionally, this thread can be woken up for processing withWakeMessageHandler(used by thenetthread loop).
The PeerLogicValidation::ProcessMessages and ProcessMessage functions are really complex. They have a big part of the p2p functionality and application logic.
Each CNode has a Poisson delay set for sending invs to it. When this delay expires for one node, all of the nodes will be processed again.
The addcon thread opens connections to peers specified with the addnode command line parameter and RPC command. Nodes added using addnode (or -connect) are protected from DoS disconnection and are not required to be full nodes as other outbound peers are.
The opencon thread will do two different things if the -connect parameter is specified. If it's specified, it will enter a loop that will connect to the
specified IPs, and any further IPs specified with the addnode RPC command; exiting the loop will terminate the thread. Otherwise, it will enter into "normal operation" mode, which has an outer
loop which finds seed nodes, calculates nodes to try, and an inner loop that will find one valid connectable address; after that, the outer loop will finish with a connection attempt to that address.
Benefits and impact
The net and msghand threads work in parallel, neatly separating the processing of network-level streams and application-level messages. Looking at the details
of the msghand thread, it is evident that the processing of received messages is essentially single-threaded. This includes mempool admissions of transactions, block validation, or the ability
to serve simple peer queries (e.g., GETDATA) while the processing of another message is running.
The benefits could possibly be:
- A great increase in transaction admission rate. The longest steps of transaction admission are UTXO lookups (IO bound) and signature verification (CPU bound) - if they could be done in parallel (while the actual mempool data structure admission remained single-threaded), then the admission could scale out linearly on multicore CPUs, up until other limits are hit (mempool checks and inserts, ...). This cannot be done if only one single message (a TX in this case) can be processed.
- The ability to process blocks in parallel. Currently, if two blocks arrive in short order, one cannot be processed until the other has finished processing. There are tradeoffs to be made here, it's a functionality that might be useful (for example if I receive one big and then one smaller block, I'd might like to start mining on the smaller right away).
- The ability to serve simple peer and RPC requests even while some heavy processing is being done. Currently, if a peer asks for INVs, HEADERS or GETDATA, they cannot be satisfied if the processing of a big block is happening. There is no other technical reason for this though, and while it could put a small load on top of my block processing, it would optimize the network as a whole. This is a concrete bottleneck to network propagation in schemes like CompactBlocks.
bitcoind is a peer-to-peer application, so the network processing is central to both functionality and security. Reworking the architecture of these central aspects comes with a set of costs and risks:
- The functionality needs to be either preserved or, where changes are made, they need to be accurately documented. Looking at the
msghandloop, which works in strange ways, this could be difficult and nuanced. Would a different ordering of processing affect the functionality? - The security needs to be preserved. In particular, all known DoS vectors need to be guarded for. This includes all of the explicitly implemented DoS protections, as well as some that could arise from changing the architecture (for example, currently, all peers' messages will be processed on every loop, so no one peer can "overwhelm" the others in my queues).
Depending on how we want to go about it, all known and anticipated DoS vectors would need to be protected from with either:
- Manual verification of the code, while it changes; cheaper but more error prone.
- Automated verification via encoded tests; possibly more reliable but worth much more initial effort.
There is always the possibility of introduction of a DoS vector that is both unknown and unanticipated, though.
Moreover, there is always the possibility of introducing programming errors, especially in a big refactor. There are precedents for this, and the reputation hits this could lead to are quite important. This is very important, especially while the Bitcoin Cash Node software remains, to the best of my knowledge, the main node used for mining, and needs to be rock-solid reliable as it has always been.
There is distinct but related architectural concern that will also need to be addressed to fully take advantage of an architectural rework: fine-grained locking. The net part of the current implementation
relays on a multitude of fine locks for synchronization; on the other hand, the msghand/processing part grossly uses a single big lock (cs_main) most
of the time. Even if we do parallelize the message processing, we would see little benefit without also implementing finer grained locks around it. The impact of doing so is out of the scope of the current report.
Appendix: Description of relevant classes and files
In the following is a strictly signifies that a class extends another. has a strictly signifies composition.
A CNetAddr (in netaddress.h) represents a network address (IPv6, or IPv4 using mapped IPv6 range (::FFFF:0:0/96)).
A CService (in netaddress.h) is a CNetAddr that also has a (TCP) port.
A CAddress (in protocol.h) is a CService "with information about it as peer" (i.e. ServiceFlags).
A CAddrInfo (in addrman.h) is a CAddress with "extended statistics". It is serializable and managed by CAddrMan (in
addrman.h) which, among other things, is what reads and writes to the peers.dat file (via CAddrDB).
A CSubNet (in netaddress.h) has a CNetAddr and a netmask. It's used by the BanMan (in
banman.h), via CBanDB, and also other parts of the application, like the http server
The netbase.h file has a number of functions for basic networking.
A NetEventsInterface (in net_processing.h) is an "interface for message handling". The PeerLogicValidation, the class that does most of the network processing
(in net_processing.cpp) is a NetEventsInterface (and also is a CValidationInterface); it is the only class that implements this interface.
A CNetMessage (in net.h) contains partial or complete messages. While data is being received, the message can be left partial, until the next read. A complete message has a CMessageHeader and
the CDataStream.
A CNode (in net.h) represents information about a network peer. It has a CAddress and data structures for exchange of messages and raw data.
A CConnman (in net.h) manages the connections to peers. It has a vector of CNode pointers, and methods to connect, disconnect and otherwise manage
connections and peers.
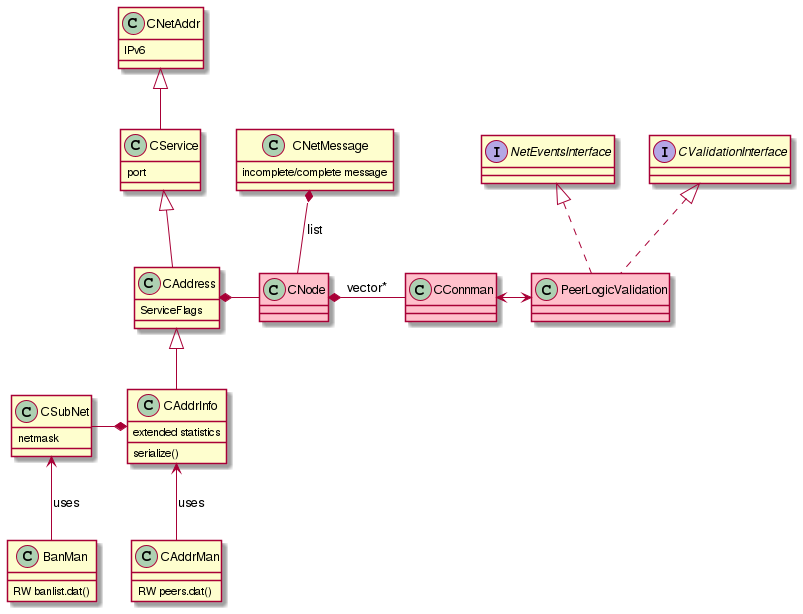
The above image presents the relevant classes and their interactions. The most important are figured in pink.
Links:
- Repository link of this announcement: GitLab